STATA 102
Alosias A, Behavioral Development Lab
The STATA 102 introduces foundational Stata concepts and will allow the user to complete essential data manipulation and analysis tasks.
1. Create a do-file
A do file lists and executes Stata commands. It is a convenient and efficient alternative to typing commands in the Stata command box. By storing commands for a particular analysis in a do file, you can easily replicate your results, re-run your analysis with modifications and elaborations, or repeat it after correcting errors. A do file is a separate file that has a “.do” extension.
To create a do file, click on the New Do-file Editor icon at the top of the Stata window. Alternatively, you can click on Window, then on Do-file Editor, then on New Do-file Editor or short-cut keys Ctrl + 9 to open New Do-file Editor.
This blank text document is your do file. You can write (and edit) commands in this file as you would in the Stata command window, in the order that you would like to execute them.
We can start by typing clear all set more off so we clear our workspace and sysuse auto file from STATA example datasets to obstain a frequency table for the variable "price".
To execute all the commands in your do file sequentially in Stata, press the “Execute (do)” icon, located in the toolbar of the Do-file Editor window. Alternatively, you can click on Tools in the Do-file Editor window, then on Execute (do).
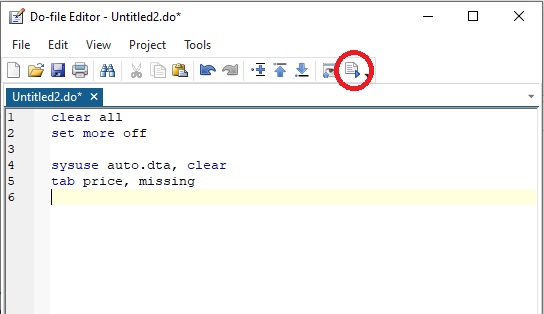
Useful tip: Short-cut keys to execute all the commands, press Ctrl + D from keyboard.
There are three ways to add comments in Stata:
-
Double forward slash – //
Anything written right after the double forward slash gets treated as a comment if it is in the same line as the forward slashes.
// This is a comment correctly added.
-
Asterisk – *
Asterisks provide limited commenting capability in that they only work if added at the very beginning of a line.
* This is a comment that can be entered through Stata’s command box or the do file.
-
A forward slash and an asterisk – /* comment */
Any text encased between a forward slash and asterisk will be treated as a comment. Not only that, this style of commenting also allows you to take your comment to a new line. You can therefore comment out multiple lines of text or code as one comment.
/* This is the first line of this comment.
This is the second line of this comment.
*/
Anything written right after the double forward slash gets treated as a comment if it is in the same line as the forward slashes.
// This is a comment correctly added.
Asterisks provide limited commenting capability in that they only work if added at the very beginning of a line.
* This is a comment that can be entered through Stata’s command box or the do file.
Any text encased between a forward slash and asterisk will be treated as a comment. Not only that, this style of commenting also allows you to take your comment to a new line. You can therefore comment out multiple lines of text or code as one comment.
/* This is the first line of this comment.
This is the second line of this comment.
*/
2. Create a dataset
The answer to this question involves the use of the input command.
Let’s say that you want to enter the following data:
x y
32 56
26 67
34 61
39 58
Here is how you would do it:
input x y
32 56
26 67
34 61
39 58
29 58
end
x y 32 56 26 67 34 61 39 58
input x y 32 56 26 67 34 61 39 58 29 58 end
list
x y
1. 32 56
2. 26 67
3. 34 61
4. 39 58
5. 29 58
save data.dta, replace
3. Data Manipulation Commands
Let’s illustrate use of the process using example STATA auto dataset.
sysuse auto, clear
(i) rename
The command rename changes the name of an existing variable old_varname to new_varname; the contents of the variable are unchanged.
rename old_varname new_varname
rename rep78 repair
(ii) replace
The replace command changes the contents or values of an existing variable.
generate new_var = 0
replace new_var = 1
(iii) lebel
(a) Assign a label to the data file currently in memory - syntex: label data "Label for dataset here"
label data "1978 auto data"
(b) Assign a label to the variable - syntex: label variable var_name "Label for variable here"
label variable foreign "the origin of the car, foreign or domestic"
(c) Create the value label and assign it to the variable.
label define foreignl 0 "domestic car" 1 "foreign car"
label values foreign foreignl
(iv) tostring & destring
(a) The tostring command converts variables in varlist from numeric to string. Variables in varlist that are already string will not be converted.
tostring varlist , generate(newvarlist)
tostring mpg, generate(mpg_str)or
tostring varlist , replace
tostring mpg, replace
(b) destring converts variables in varlist from string to numeric. If varlist is not specified, destring will attempt to convert all variables in the dataset from string to numeric.
destring varlist , generate(newvarlist)
destring mpg_str, generate(mpg_num)or
destring varlist , replace
destring mpg, replace
(v) decode, encode and recode
(a) decode: Numeric variable to string variable
decode varname, generate(newvar)
(b) encode: String variable to numeric variable
encode varname, generate(newvar)
Useful tip: Do not use encode if varname contains numbers that merely happen to be stored as strings; instead use destring
(c) recode: Recode categorical variables
recode varlist (# = #) (# = #) ..., generate(newvar)
(vi) bysort
When you want to use by var: command you need to first sort var beforw uaing the by, however, it is possible to the by and the sort into a single command. by and bysort are really the same command; bysort is just by with the sort option.
bysort variable1: summarize variable2
(vii) duplicates
duplicates reports, displays, lists, tags, or drops duplicate observations, depending on the subcommand specified. Duplicates are observations with identical values either on all variables if no varlist is specified or on a specified varlist.
(a) duplicates report: the duplicates report command to see the number of duplicate rows in the dataset. This is followed by duplicate reports variable, which gives the number of replicate rows by the variables specified; in this instance we have just "variable".
duplicates report
duplicates report variable_name
(b) duplicates list: list duplicate observations with the duplicates list command.
duplicates list
duplicates list variable_name
(c) duplicates tag: To have an output like that given from duplicates list, we use the duplicates tag command to create a new variable that assigns "1" if the id is duplicated, and "0" if it appears once.
duplicates tag variable_name, gen(duplicate_id)
(d) duplicates drop: we can use the duplicates drop command to drop the duplicate observations. The command drops all observations except the first occurrence of each group with duplicate observations.
duplicates drop
duplicates drop variable_name